I am convinced that anyone who is starting to learn programming, regardless of their goal, they will likely need to have a basic understanding of networking.
I’ll cover some basics, how browsers work, what’s operating system’s role in all of this, as I delve deeper into this topic throughout this post, we will explore various aspects of networking in greater detail.
At the end, you will be able to implement a protocol such as HTTP!
Let’s start with your smartphone
Your phone must have a WiFi and Bluetooth module, they’re little chips located somewhere on device’s motherboard. Operating system powers them up and makes them available for your applications.
Apps that require internet connection utilize the low level API provided by the OS to send (and receive) data, which is then sent through the WiFi module before being transmitted to your router and ultimately reaching its final destination.
Data representation in network transmission
Of course all digital information consists of nothing but a series of zeros and ones, but it’s crucial to interpret these binary sequences.
That’s where the usefulness of internet packets AKA IP datagrams comes in. They contain the actual payload, following with source and destination information in the form of IP addresses, as well as other additional information that I’ll not cover in this post.
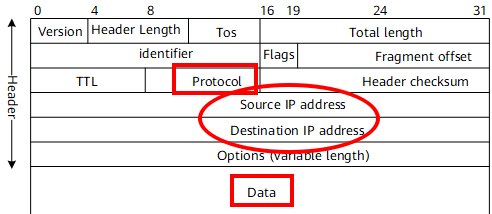
So, every packet can be read by any other device, such as router then addressed to a specific destination using that IP Header… Routers in the network use this information to determine the next hop for the packet, and the process repeats until the packet reaches its final destination.
The Vital Role of TCP in the Internet
There are many protocols on top of IP, but most used ones are TCP and UDP.
TCP and UDP packets have a similar structure. Both protocols use the same IP (Internet Protocol) packet format to transmit data, which includes a header that contains information about the source and destination of the data, as well as error-checking information. However, the main difference between TCP and UDP packets is the type of transport layer protocol used to transmit the data.
TCP provides a reliable, ordered delivery of data,
while UDP provides a fast, but unreliable delivery of data.
So, if latency is important like for online games, voice chats and similar - UDP is considered a better option…
But, on top of TCP are built the most used high-level protocols of all time:
- HTTP (mostly used in web for transferng HTMLs, static content, etc.)
- FTP (file transfer protocol, obviously for transfering files)
- SMTP (protocol designed for mailing)
Because TCP provides true reliability, you have the ability to define your own protocol. This is why there are many application-layer protocols built on top of it, it’s a lot easier than using UDP, you don’t have to worry about any lost or duplicate packets.
You can actually see almost all the protocols on different layers:

How do browsers work?
Let’s finally start with something useful lmao.
Every web browser must have an address bar where you can type in a URL and be taken directly to the page. If the input does not resemble a URL, the browser will redirect you to a search engine with your entered query (Google or whatever is in your browser settings).
Domains
For example - you’re heading to https://google.com. Before the :// you define the protocol you want to use, most likely it will be HTTPS (also could be ftp, or smtp and so on…).
Then your device gets IP address of the domain name google.com, almost certainly it already has the address cached somewhere. So no requests will be made to DNS servers.
Security
Well, with the IP address obtained, browser can make a TCP connection to the server and start making HTTP requests to it. There’s a security layer sitting in between TCP and HTTP called SSL or the improved one TLS.
Without these, anyone including your internet provider could read contents of HTTP in plain text.
Also there are many other important security mechanisms like CORS that restricts access to resources on a web page from a different domain, but that’s another topic.
Resources
When visiting a website, the browser initiates a single GET request to retrieve the main HTML file. I guess we all know how a HTML file looks like… There’s a header part and the body part.
We are particularly interested in the header section as it contains various tags that inform the browser about additional resources required to fully and accurately render the page.
(E.g. link tag mostly for CSS and favicons and script with src attribute for JS.)

Those extra resources are asked also by the browser in form of a HTTP request, so it is necessary to understand that server can’t push any data to the client without client asking!
(the newer versions of HTTP somewhat allow this operation)
Rendering
This is the pipeline how your browser renders everything with requested HTML and CSS.
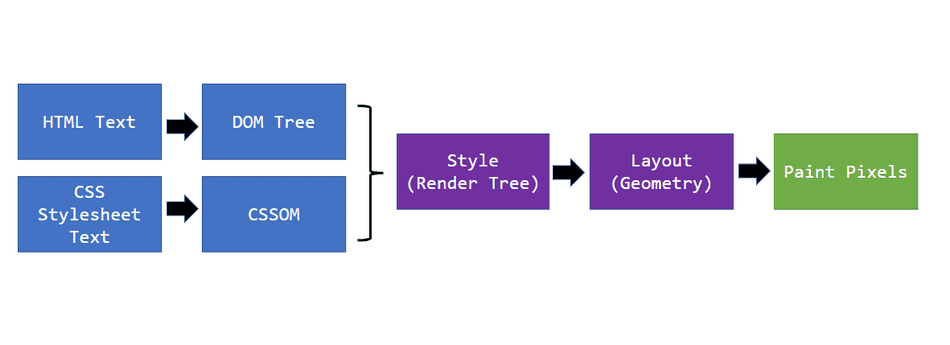
Also here’s awesome post by Mozilla if you want to learn more.
HTTP Breakdown
Now that you have gained a little bit knowledge about networking (or perhaps you already have a good understanding of this) - we can look in detail how HTTP works.
Here’s the flow:
- Server-Client TCP connection is opened.
- HTTP data is transfered
- Connection is kept alive for possible future requests
HTTP is text-based protocol - it’s just a string!
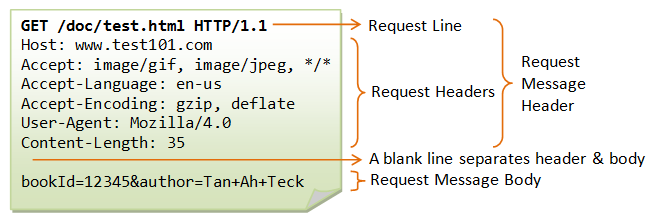
^^^
This is a request made by a browser.
Request line and request headers are just separated by \r\n, so the actual request looks like this:
GET /doc/test.html HTTP/1.1\r\nHost:...
Okay, on the first line you can notice GET keyword. It’s just a way of telling what request will do -
GET usually means we’re telling the server that we want to GET something, whether it be HTML, CSS, JS, images - doesn’t matter.
POST we’re sending data to the server (could be login information, image upload, etc.)
This isn’t a strict “rule”, so it depends how a web server is written. Some websites do retreive the data with POST request 🤦
Next, the path is specified where the resource is located on, in this case /doc/test.html.
And finally the HTTP version, here’s a good article to see what are differences between versions.
And that’s enough of what is required to make a legit HTTP request to a server!
Writing a web server
You probably SHOULDN’T write a web server from scratch as there are so fucking many of them, just to name a few:
Apache HTTP Server, Nginx, Lighttpd, Cherokee, Caddy, Tomcat, Glassfish, WildFly, Node.js, Ruby on Rails, Django, Flask, Express.js, Litespeed, Yaws, Cowboy, Gunicorn, Hiawatha, Swarm and more.
Just use whichever you find the best for you.
But for learning purposes, let’s write one more!
To be honest, this won’t be a complete web server with multithreading, routing, authorization and other goodies that provide servers listed above.
So we’re writing a simple program that will listen for incoming connections, parse HTTP and return back a HTML file.
Let’s do it in Rust, why not.
Create a socket
Most programming languages provide some kind of a low-level API to create sockets, send data through them etc. In Python there’s socket from standard library, in Rust we have TcpListener from std::net.
So, let’s make it usable in our code as “TcpListener”:
|
|
TcpListener provides bind method, which returns a new TcpListener bound to an address:
|
|
Accepting new connections (clients)
As we can see in docs, TcpListener has incoming method which returns Incoming iterator so we can iterate on this thing for incoming connections! Isn’t that awesome!?
|
|
Great, we have established a bidirectional communication channel with the client that is both readable and writable.
Parsing HTTP
As soon as connection is opened, we need to read the HTTP request sent by the browser.
There are several ways to do it. I’ll use BufReader, it can be used to wrap a stream and provide more convenient reading methods, such as read_line and read_until.
|
|
As we can see it accepts mutable reference to our stream we opened. Now we have a beautiful API to read those bytes >:)
To parse HTTP, it has to be splitted into multiple lines as I explained before. One parameter == one line…
We only care about the first line as it contains the path we need.
|
|
Let’s print request_line to stdout and try to connect with browser to our “server” :D
|
|
Aaaaand then type localhost:5550 in browser to connect:
|
|
Yay!
Because we send nothing in return, browser is retrying to send request over and over until it reaches some timeout value.
That’s the reason why we see multiple outputs.
So let’s fix that.
Returning appropriate HTML file
“The browser is like a hungry beast, anxiously pacing back and forth, eagerly awaiting its next meal in the form of a response.”
Uhm, alright. Time to write some HTML. Let’s make two files - index.html and 404.html.
We’ll check later the path browser requested, if it is / then index.html will be returned, otherwise - 404.html.
|
|
For 404.html just put into <p> 404 message or whatever….
Let’s decade which file to send. That would be a simple if statement in our case.
|
|
.trim() is here to eliminate CLRF, so from this GET / HTTP/1.1\r\n to this GET / HTTP/1.1.
Ok, let’s now compose a legit HTTP response!
Response structure:
- First line should be HTTP version followed with status code
- Below are HTTP header parameters, we do not need them now
- And after those - as you might have guessed, it’s the HTTP body.
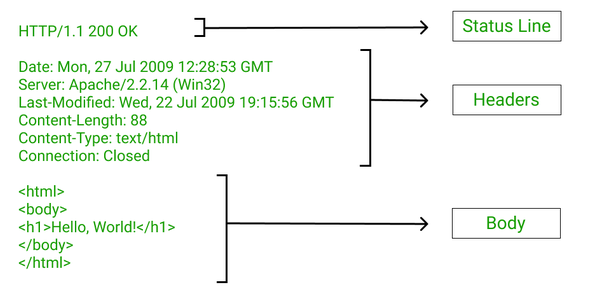
Status line:
|
|
HTTP header and body separator:
|
|
And index.html contents:
|
|
It should look like this:
|
|
Finally let’s send response to byte stream!!!
|
|
For “Not Found” page is almost the same:
|
|
Here’s full code working code
|
|
And that’s pretty much it.
The end
In conclusion, understanding the fundamentals of networking and computer communication is crucial for anyone looking to work in the field of technology. By exploring the basics of routing, packets, and network protocols, you have gained a valuable foundation of knowledge that will serve as the basis for further learning and development.
ALSO, the process of writing your own HTTP server can seem daunting, but by learning about socket programming, HTTP request and response structures, and the handling of client-server communication, you have gained a deeper understanding of the mechanics behind the World Wide Web and the internet.
I hope it was an interesting read! Bye.